
El SEO es una práctica compleja, vasta y, a veces, misteriosa. Hay muchos aspectos del SEO que pueden generar confusión.
No todo el mundo estará de acuerdo con lo que implica el SEO: dónde termina el SEO técnico y comienza el desarrollo.
Lo que tampoco ayuda es la gran cantidad de información errónea que circula. Hay muchos “expertos” en línea y no todos deberían llevar ese título autoproclamado. ¿Cómo sabes en quién confiar?
Incluso los empleados de Google a veces pueden aumentar la confusión. Les cuesta definir sus propias actualizaciones y sistemas y, a veces, ofrecen consejos que entran en conflicto con declaraciones anteriores.
Los peligros de los mitos del SEO
El problema es que simplemente no sabemos exactamente cómo funcionan los motores de búsqueda. Debido a esto, gran parte de lo que hacemos como profesionales de SEO es prueba y error y conjeturas fundamentadas.
Cuando aprende sobre SEO, puede resultar difícil probar todas las afirmaciones que escucha.
Ahí es cuando los mitos del SEO comienzan a afianzarse. Antes de que te des cuenta, estarás diciéndole con orgullo a tu superior directo que planeas “optimizar la descripción general de IA” del texto de tu sitio web.
Los mitos del SEO se pueden romper muchas veces con una pausa y algo de consideración.
¿Cómo exactamente podría Google medir eso? ¿Eso realmente beneficiaría al usuario final de alguna manera?
En SEO existe el peligro de considerar a los motores de búsqueda como omnipotentes y, debido a esto, comienzan a crecer mitos descabellados sobre cómo entienden y miden nuestros sitios web.
¿Qué es un mito del SEO?
Antes de desacreditar algunos mitos comunes sobre el SEO, primero debemos comprender qué formas adoptan.
Sabiduría no probada
Los mitos en SEO tienden a tomar la forma de sabiduría heredada que no se prueba.
Como resultado, algo que bien podría no tener ningún impacto en generar tráfico orgánico calificado a un sitio se trata como si importara.
Factores menores desproporcionados
Los mitos de SEO también pueden ser algo que tiene un pequeño impacto en las clasificaciones orgánicas o la conversión, pero se les da demasiada importancia.
Este podría ser un ejercicio de “marcar casilla” que se considera un factor crítico en el éxito del SEO, o simplemente una actividad que solo podría hacer que su sitio avance a duras penas si todo lo demás con su competencia fuera realmente igual.
Consejos obsoletos
Los mitos pueden surgir simplemente porque lo que solía ser eficaz para ayudar a los sitios a clasificarse y generar buenas conversiones ya no lo es, pero se sigue recomendando. Puede ser que algo solía funcionar muy bien.
Con el tiempo, los algoritmos se han vuelto más inteligentes. El público es más reacio a recibir marketing.
Simplemente, lo que alguna vez fue un buen consejo ahora ha desaparecido.
Google es mal entendido
Muchas veces, el inicio de un mito es el propio Google.
Desafortunadamente, un consejo un poco oscuro o poco claro de un representante de Google se malinterpreta y se pasa por alto.
Antes de que nos demos cuenta, un nuevo servicio de optimización se está vendiendo a partir de un comentario frívolo que un empleado de Google hizo en broma.
Los mitos del SEO pueden basarse en hechos, o tal vez sean, más exactamente, leyendas del SEO.
En el caso de los mitos nacidos en Google, tiende a ser que el hecho ha sido tan distorsionado por la interpretación de la declaración por parte de la industria SEO que ya no parece información útil.
26 mitos comunes sobre SEO
Entonces, ahora que sabemos qué causa y perpetúa los mitos sobre SEO, descubramos la verdad detrás de algunos de los más comunes.
1. Los efectos de luna de miel y Sandbox de Google
Algunos profesionales de SEO creen que Google suprimirá automáticamente los nuevos sitios web en los resultados de búsqueda orgánicos durante un período de tiempo antes de que puedan clasificarse más libremente.
Otros sugieren que hay una especie de Período de Luna de Miel, durante el cual Google clasificará altamente el contenido nuevo para probar lo que los usuarios piensan de él.
El contenido se promocionaría para garantizar que más usuarios lo vean. Señales como la tasa de clics y los rebotes en las páginas de resultados del motor de búsqueda (SERP) se utilizarían para medir si el contenido es bien recibido y merece permanecer en una clasificación alta.
Sin embargo, existe el Google Privacy Sandbox. Esto está diseñado para ayudar a mantener la privacidad de las personas en línea. Esta es una zona de pruebas diferente a la que supuestamente suprime nuevos sitios web.
Cuando se le preguntó específicamente sobre el efecto luna de miel y las clasificaciones Sandbox, John Mueller respondió:
“En el mundo del SEO, esto a veces se denomina una especie de zona de pruebas en la que Google mantiene las cosas ocultas para evitar que aparezcan nuevas páginas, lo cual no es el caso.
O algunas personas lo llaman como el período de luna de miel en el que aparece contenido nuevo y a Google realmente le encanta y trata de promocionarlo.
Y nuevamente, no es el caso que estemos tratando explícitamente de promover contenido nuevo o degradarlo.
Es sólo que no lo sabemos y tenemos que hacer suposiciones.
Y luego, a veces, esas suposiciones son correctas y nada cambia realmente con el tiempo.
A veces las cosas se estabilizan un poco más abajo, a veces un poco más arriba”.
Por lo tanto, Google no promueve ni degrada de manera sistemática el contenido nuevo, pero lo que quizás esté notando es que las suposiciones de Google se basan en el resto de las clasificaciones del sitio web.
- Veredicto: ¿Oficialmente? Es un mito.
2. Penalización por contenido duplicado
Este es un mito que escucho mucho. La idea es que si tienes contenido en tu sitio web que está duplicado en otra parte de la web, Google te penalizará por ello.
La clave para comprender lo que realmente está sucediendo aquí es conocer la diferencia entre supresión algorítmica y acción manual.
Una acción manual, la situación que puede resultar en la eliminación de páginas web del índice de Google, será realizada por un humano de Google.
El propietario del sitio web será notificado a través de Google Search Console.
Una supresión algorítmica ocurre cuando su página no puede clasificarse bien debido a que ha sido detectada por un filtro de un algoritmo.
Esencialmente, tener una copia tomada de otra página web puede significar que no puedes superar a esa otra página.
Los motores de búsqueda pueden determinar que el servidor original de la copia es más relevante para la consulta de búsqueda que el suyo.
Como no hay ningún beneficio en tener ambos en los resultados de búsqueda, el tuyo se suprime. Esto no es una pena. Este es el algoritmo haciendo su trabajo.
Hay algunas acciones manuales relacionadas con el contenido, pero esencialmente copiar una o dos páginas del contenido de otra persona no las activará.
Sin embargo, es posible que le cause otros problemas si no tiene el derecho legal de utilizar ese contenido. También puede restar valor al valor que su sitio web aporta al usuario.
¿Qué pasa con el contenido duplicado en su propio sitio? Mueller aclara que el contenido duplicado no es un factor de clasificación negativo. Si hay varias páginas con el mismo contenido, Google puede elegir una como página canónica y las demás no se clasificarán.
3. La publicidad PPC ayuda a las clasificaciones
Este es un mito común. También es bastante rápido de desacreditar.
La idea es que Google favorezca a los sitios web que gasten dinero en él mediante publicidad de pago por clic. Esto es simplemente falso.
El algoritmo de Google para clasificar los resultados de búsqueda orgánicos es completamente independiente del utilizado para determinar la ubicación de los anuncios PPC.
Ejecutar una campaña de publicidad de búsqueda paga a través de Google mientras se realiza SEO podría beneficia tu sitio por otras razones, pero no beneficiará directamente tu clasificación.
4. La antigüedad del dominio es un factor de clasificación
Esta afirmación está firmemente arraigada en el campo de la “causalidad y correlación confusas”.
Debido a que un sitio web existe desde hace mucho tiempo y tiene una buena clasificación, la edad debe ser un factor de clasificación.
Google ha desmentido este mito muchas veces.
En julio de 2019, Mueller respondió a una publicación en Twitter.com (recuperada a través de Wayback Machine) que sugería que la edad del dominio era una de las “200 señales de clasificación” y decía: “No, la edad del dominio no ayuda en nada”.
La verdad detrás de este mito es que un sitio web más antiguo ha tenido más tiempo para hacer las cosas bien.
Por ejemplo, un sitio web que ha estado activo durante 10 años bien puede haber adquirido un gran volumen de vínculos de retroceso relevantes a sus páginas clave.
Es poco probable que un sitio web que haya estado funcionando durante menos de seis meses pueda competir con eso.
El sitio web más antiguo parece tener una mejor clasificación y la conclusión es que la edad debe ser el factor determinante.
5. El contenido con pestañas afecta las clasificaciones
Esta idea tiene raíces que se remontan a mucho tiempo atrás.
La premisa es que Google no asignará tanto valor al contenido que se encuentra detrás de una pestaña o un acordeón.
Por ejemplo, texto que no se puede ver en la primera carga de una página.
Google volvió a desacreditar este mito en marzo de 2020, pero ha sido una idea polémica entre muchos profesionales de SEO durante años.
En septiembre de 2018, Gary Illyes, analista de tendencias para webmasters de Google, respondió a un hilo de tweets sobre el uso de pestañas para mostrar contenido.
Su respuesta:
“Que yo sepa, nada ha cambiado aquí, Bill: indexamos el contenido y su peso se considera completamente para la clasificación, pero es posible que no aparezca en negrita en los fragmentos. Es otra cuestión, más técnica, de cómo el sitio muestra ese contenido. La indexación tiene limitaciones”.
Si el contenido es visible en HTML, no hay razón para suponer que se está devaluando simplemente porque no es evidente para el usuario en la primera carga de la página. Este no es un ejemplo de encubrimiento y Google puede recuperar fácilmente el contenido.
Siempre que no haya nada más que impida que Google vea el texto, debe tener el mismo peso que la copia, que no está en pestañas.
¿Quieres más aclaraciones sobre esto? Entonces consulte este artículo de SEJ que analiza este tema en detalle.
6. Google utiliza datos de Google Analytics en las clasificaciones
Este es un temor común entre los dueños de negocios.
Estudian sus informes de Google Analytics. Sienten que su tasa de rebote promedio en todo el sitio es demasiado alta o que su tiempo en la página es demasiado bajo.
Por lo tanto, les preocupa que Google perciba que su sitio es de baja calidad debido a eso. Temen no obtener una buena clasificación por eso.
El mito es que Google utiliza los datos de su cuenta de Google Analytics como parte de su algoritmo de clasificación.
Es un mito que existe desde hace mucho tiempo.
Illyes ha vuelto a desacreditar esta idea simplemente diciendo: “No utilizamos *nada* de Google Analytics. [sic] en el “algo”.
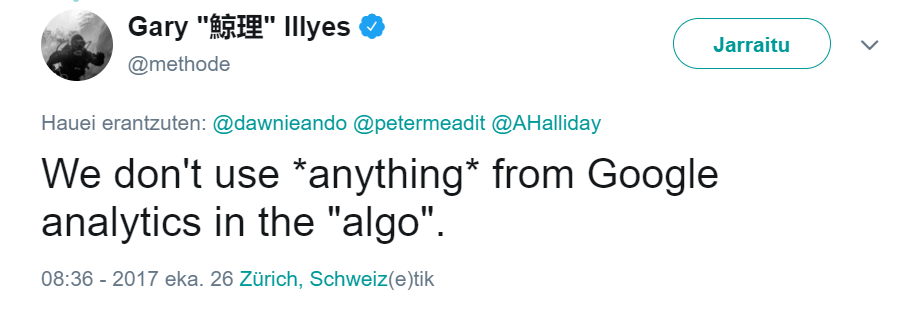 Imagen de Twitter.com recuperada a través de Wayback Machine, junio de 2024
Imagen de Twitter.com recuperada a través de Wayback Machine, junio de 2024Más recientemente, John Mueller disipó esta idea una vez másdiciendo: “Eso no va a suceder” cuando recibió la sugerencia de decirle a los profesionales de SEO que GA4 es un factor de clasificación que mejoraría su aceptación.
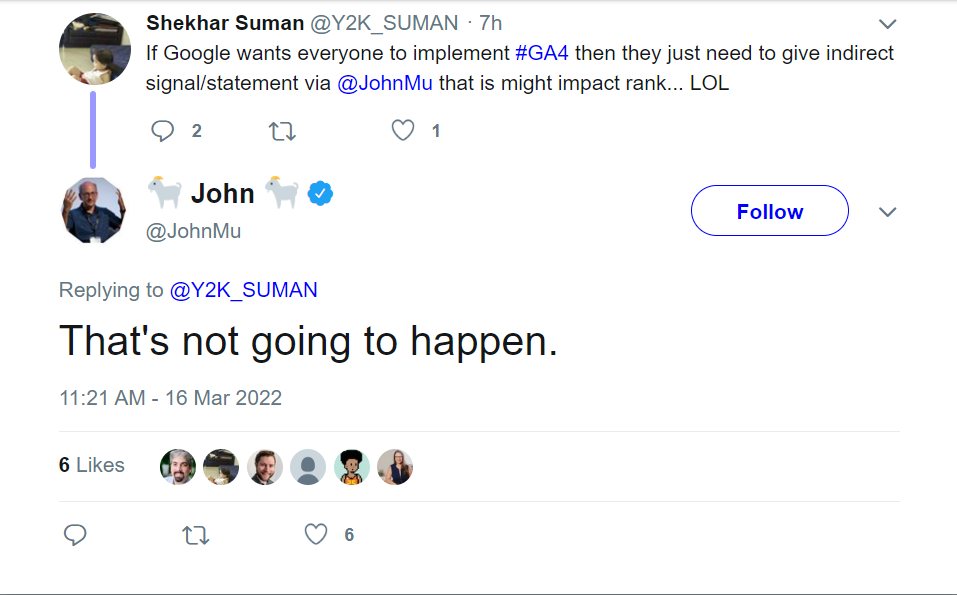 Imagen de Twitter.com recuperada de Wayback Machine, junio de 2024
Imagen de Twitter.com recuperada de Wayback Machine, junio de 2024Si pensamos en esto de manera lógica, utilizar los datos de Google Analytics como factor de clasificación sería realmente difícil de controlar.
Por ejemplo, el uso de filtros podría manipular los datos para que parezca que el sitio funciona de una manera que en realidad no es así.
¿Qué es un buen rendimiento de todos modos?
Un alto “tiempo en la página” puede ser bueno para algunos contenidos de formato largo.
Un bajo “tiempo en la página” podría ser comprensible para contenido más corto.
¿Está alguno bien o mal?
Google también necesitaría comprender las complejas formas en que se configuró cada cuenta de Google Analytics.
Es posible que algunos excluyan a todos los bots conocidos y otros no. Algunos pueden usar dimensiones personalizadas y agrupaciones de canales, y otros no han configurado nada.
Usar estos datos de manera confiable sería extremadamente complicado. Considere los cientos de miles de sitios web que utilizan otros programas de análisis.
¿Cómo los trataría Google?
Este mito es otro caso de “causalidad, no correlación”.
Una alta tasa de rebote en todo el sitio puede ser indicativo de un problema de calidad, o puede que no lo sea. El poco tiempo en la página podría significar que su sitio no es atractivo o que su contenido es rápidamente digerible.
Estas métricas le dan pistas sobre por qué es posible que no esté en una buena clasificación, no son la causa.
7. Google se preocupa por la autoridad de dominio
PageRank es un algoritmo de análisis de enlaces utilizado por Google para medir la importancia de una página web.
Google solía mostrar la puntuación de PageRank de una página con un número de hasta 10 en su barra de herramientas. Dejó de actualizar el PageRank que se muestra en las barras de herramientas en 2013.
En 2016, Google confirmó que la métrica de la barra de herramientas PageRank no se utilizaría en el futuro.
A falta de PageRank, se han desarrollado muchas otras puntuaciones de autoridad de terceros.
Los más conocidos son:
- Puntuaciones de autoridad de dominio y autoridad de página de Moz.
- Flujo de confianza y flujo de citas de Majestic.
- Clasificación de dominio y clasificación de URL de Ahrefs.
Algunos profesionales de SEO utilizan estos…
Con información de Search Engine Journal.
Leer la nota Completa > 26 mitos comunes sobre SEO, desacreditados


")
 informan problemas de recopilación de datos")

{kind=link}