
Comprender cómo utilizar el archivo robots.txt es crucial para la estrategia de SEO de cualquier sitio web. Los errores en este archivo pueden afectar la forma en que se rastrea su sitio web y la apariencia de búsqueda de sus páginas. Por otro lado, hacerlo bien puede mejorar la eficiencia del rastreo y mitigar los problemas de rastreo.
Google recordó recientemente a los propietarios de sitios web la importancia de utilizar robots.txt para bloquear URL innecesarias.
Entre ellas se incluyen páginas para agregar al carrito, iniciar sesión o pagar. Pero la pregunta es: ¿cómo se utiliza correctamente?
En este artículo, lo guiaremos en todos los matices de cómo hacerlo.
¿Qué es Robots.txt?
El robots.txt es un archivo de texto simple que se encuentra en el directorio raíz de su sitio y les dice a los rastreadores qué se debe rastrear.
La siguiente tabla proporciona una referencia rápida a las directivas clave de robots.txt.
| Directiva | Descripción |
| Agente de usuario | Especifica a qué rastreador se aplican las reglas. Ver tokens de agente de usuario. El uso de * apunta a todos los rastreadores. |
| Rechazar | Impide que se rastreen las URL especificadas. |
| Permitir | Permite rastrear URL específicas, incluso si un directorio principal no está permitido. |
| Mapa del sitio | Indica la ubicación de su mapa del sitio XML ayudando a los motores de búsqueda a descubrirlo. |
Este es un ejemplo de robot.txt de ikea.com con múltiples reglas.
Tenga en cuenta que robots.txt no admite expresiones regulares completas y solo tiene dos comodines:
- asteriscos
- que coincide con 0 o más secuencias de caracteres.
Signo de dólar ($), que coincide con el final de una URL.
Además, tenga en cuenta que sus reglas distinguen entre mayúsculas y minúsculas, por ejemplo, “filter=” no es igual a “Filter=”.
Orden de precedencia en Robots.txt
Al configurar un archivo robots.txt, es importante saber el orden en el que los motores de búsqueda deciden qué reglas aplicar en caso de reglas conflictivas.
Siguen estas dos reglas clave:
1. Regla más específica
User-agent: *
Disallow: /downloads/
Allow: /downloads/free/Se aplicará la regla que coincida con más caracteres en la URL. Por ejemplo:
En este caso, la regla “Permitir: /descargas/gratis/” es más específica que “No permitir: /descargas/” porque apunta a un subdirectorio.
Google permitirá el rastreo de la subcarpeta “/descargas/gratis/” pero bloqueará todo lo demás en “/descargas/”.
2. Regla menos restrictiva
User-agent: *
Disallow: /downloads/
Allow: /downloads/Cuando varias reglas son igualmente específicas, por ejemplo:
Google elegirá el menos restrictivo. Esto significa que Google permitirá el acceso a /descargas/.
¿Por qué es importante Robots.txt en SEO?
El bloqueo de páginas sin importancia con robots.txt ayuda al robot de Google a centrar su presupuesto de rastreo en partes valiosas del sitio web y en el rastreo de páginas nuevas. También ayuda a los motores de búsqueda a ahorrar potencia informática, contribuyendo a una mejor sostenibilidad.
Imagina que tienes una tienda online con cientos de miles de páginas. Hay secciones de sitios web como páginas filtradas que pueden tener una infinidad de versiones.
Esas páginas no tienen un valor único, esencialmente contienen contenido duplicado y pueden crear un espacio de rastreo infinito, desperdiciando así los recursos de su servidor y del robot de Google.
Ahí es donde entra en juego el archivo robots.txt, que evita que los robots de los motores de búsqueda rastreen esas páginas.
Si no lo hace, Google puede intentar rastrear una cantidad infinita de URL con valores de parámetros de búsqueda diferentes (incluso inexistentes), lo que provocará picos y un desperdicio del presupuesto de rastreo.
Cuándo utilizar Robots.txt
Como regla general, siempre debes preguntar por qué existen ciertas páginas y si tienen algo que valga la pena para que los motores de búsqueda las rastreen e indexen.
- Si partimos de este principio, ciertamente, siempre deberíamos bloquear:
- URL que contienen parámetros de consulta como:
- Búsqueda interna.
- URL de navegación facetadas creadas mediante opciones de filtrado u clasificación si no forman parte de la estructura de URL y la estrategia de SEO.
- URL de acción como agregar a la lista de deseos o agregar al carrito.
- Partes privadas del sitio web, como páginas de inicio de sesión.
- Archivos JavaScript que no son relevantes para el contenido o la representación del sitio web, como scripts de seguimiento.
Bloquear scrapers y chatbots de IA para evitar que utilicen su contenido con fines de capacitación.
Profundicemos en cómo puede utilizar robots.txt para cada caso.
1. Bloquear páginas de búsqueda interna
El paso más común y absolutamente necesario es bloquear las URL de búsqueda interna para que Google y otros motores de búsqueda rastreen, ya que casi todos los sitios web tienen una función de búsqueda interna.
https://www.example.com/?s=googleEn los sitios web de WordPress, suele ser un parámetro “s” y la URL tiene este aspecto:
Gary Illyes de Google ha advertido repetidamente que se bloqueen las URL de “acción”, ya que pueden hacer que el robot de Google las rastree indefinidamente, incluso URL inexistentes con diferentes combinaciones.
User-agent: *
Disallow: *s=*- Esta es la regla que puede utilizar en su archivo robots.txt para bloquear el rastreo de dichas URL: El Agente de usuario: *
- La línea especifica que la regla se aplica a todos los rastreadores web, incluidos Googlebot, Bingbot, etc. El No permitir: *s=*
La línea indica a todos los rastreadores que no rastreen ninguna URL que contenga el parámetro de consulta “s=”. El comodín “*” significa que puede coincidir con cualquier secuencia de caracteres antes o después de “s=”. Sin embargo, no coincidirá con las URL con “S” mayúscula como “/?S=”, ya que distingue entre mayúsculas y minúsculas.
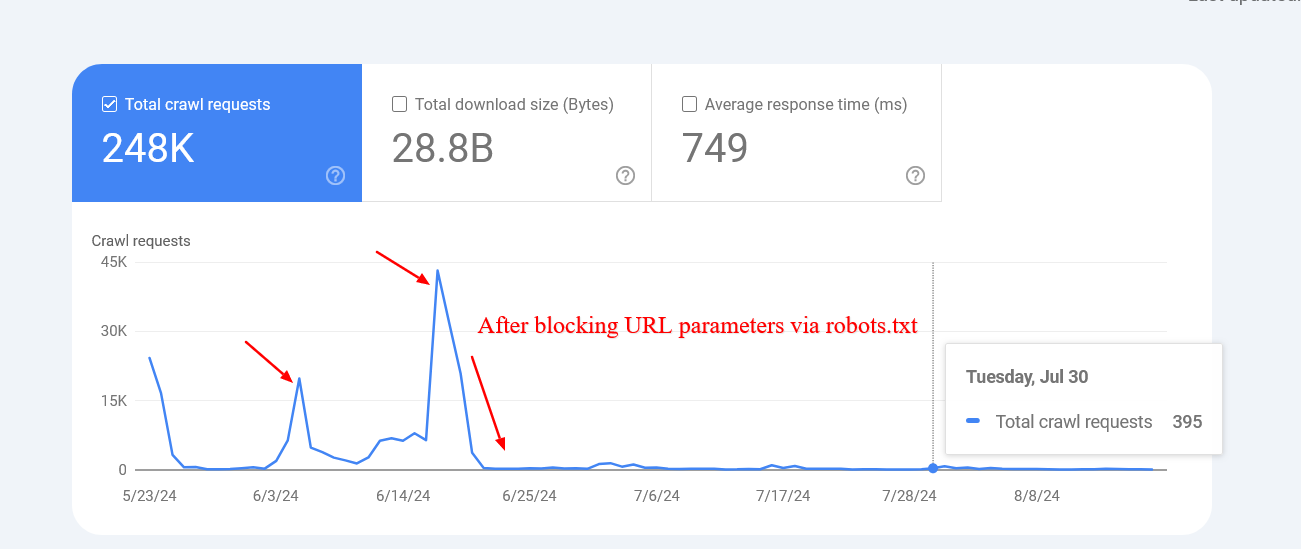 Captura de pantalla del informe de estadísticas de rastreo
Captura de pantalla del informe de estadísticas de rastreoCaptura de pantalla del informe de estadísticas de rastreo
Tenga en cuenta que Google puede indexar esas páginas bloqueadas, pero no necesita preocuparse por ellas, ya que se eliminarán con el tiempo.
2. Bloquear URL de navegación por facetas
La navegación por facetas es una parte integral de cada sitio web de comercio electrónico. Puede haber casos en los que la navegación por facetas sea parte de una estrategia de SEO y tenga como objetivo la clasificación para búsquedas generales de productos.
Por ejemplo, Zalando utiliza URL de navegación facetadas para opciones de color para clasificar palabras clave generales de productos como “camiseta gris”.
Sin embargo, en la mayoría de los casos, este no es el caso, y los parámetros de filtro se utilizan simplemente para filtrar productos, creando decenas de páginas con contenido duplicado.
Técnicamente, esos parámetros no son diferentes de los parámetros de búsqueda internos con una diferencia, ya que puede haber varios parámetros. Debes asegurarte de no permitirlos a todos.
User-agent: *
Disallow: *sortby=*
Disallow: *color=*
Disallow: *price=*Por ejemplo, si tiene filtros con los siguientes parámetros “ordenar”, “color” y “precio”, puede utilizar este conjunto de reglas:
Según su caso específico, puede haber más parámetros y es posible que deba agregarlos todos.
¿Qué pasa con los parámetros UTM?
Los parámetros UTM se utilizan con fines de seguimiento.
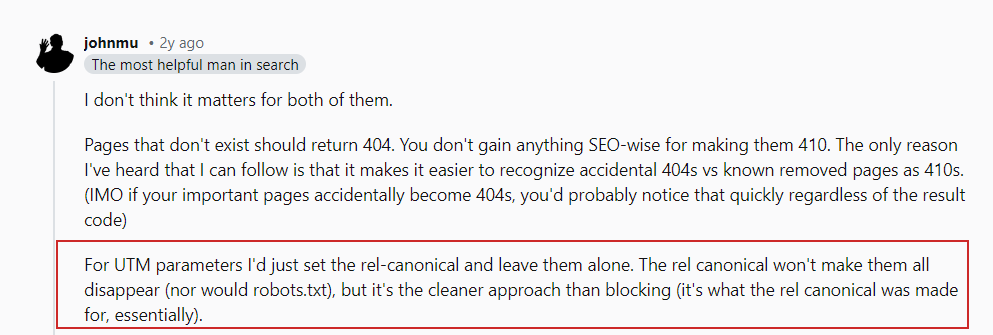 John Mueller sobre los parámetros UTM
John Mueller sobre los parámetros UTMJohn Mueller sobre los parámetros UTM
Solo asegúrese de bloquear cualquier parámetro aleatorio que utilice internamente y evite vincular internamente a esas páginas, por ejemplo, vincular desde las páginas de su artículo a su página de búsqueda con una página de consulta de búsqueda “https://www.example.com/?s=google .”
3. Bloquear URL de PDF
Supongamos que tiene muchos documentos PDF, como guías de productos, folletos o documentos descargables, y no desea que se rastreen.
User-agent: *
Disallow: /*.pdf$Aquí hay una regla simple de robots.txt que bloqueará el acceso de los robots de los motores de búsqueda a esos documentos:
La línea “Disallow: /*.pdf$” indica a los rastreadores que no rastreen ninguna URL que termine en .pdf.
Al utilizar /*, la regla coincide con cualquier ruta del sitio web. Como resultado, se bloqueará el rastreo de cualquier URL que termine en .pdf.
User-agent: *
Disallow: /wp-content/uploads/*.pdf$
Allow: /wp-content/uploads/2024/09/allowed-document.pdf$Si tiene un sitio web de WordPress y desea no permitir archivos PDF desde el directorio de carga donde los carga a través del CMS, puede usar la siguiente regla:
Puedes ver que tenemos reglas contradictorias aquí.
En caso de reglas contradictorias, la más específica tiene prioridad, lo que significa que la última línea garantiza que solo se permita rastrear el archivo específico ubicado en la carpeta “wp-content/uploads/2024/09/allowed-document.pdf”.
4. Bloquear un directorio
Supongamos que tiene un punto final API donde envía sus datos desde el formulario. Es probable que su formulario tenga un atributo de acción como action=”/form/submissions/”.
User-agent: *
Disallow: /form/El problema es que Google intentará rastrear esa URL, /form/submissions/, lo cual probablemente no quieras. Puede bloquear el rastreo de estas URL con esta regla:
Al especificar un directorio en la regla No permitir, les está indicando a los rastreadores que eviten rastrear todas las páginas bajo ese directorio y no necesita usar la regla
Ya no hay comodines, como “/form/*”.
Tenga en cuenta que siempre debe especificar rutas relativas y nunca URL absolutas, como “https://www.example.com/form/” para las directivas Disallow y Allow. Tenga cuidado para evitar reglas mal formadas. Por ejemplo, usar /form sin una barra diagonal también coincidirá con una página /form-design-examples/, que puede ser una página de su blog que desea indexar.
Leer:
8 problemas comunes de Robots.txt y cómo solucionarlos
5. Bloquear las URL de cuentas de usuario
Si tiene un sitio web de comercio electrónico, es probable que tenga directorios que comiencen con “/micuenta/”, como “/micuenta/pedidos/” o “/micuenta/perfil/”.
User-agent: *
Disallow: /myaccount/
Allow: /myaccount/$
Dado que la página principal “/myaccount/” es una página de inicio de sesión que desea que los usuarios indexen y encuentren en la búsqueda, es posible que desee impedir que el robot de Google rastree las subpáginas.
Puede usar la regla No permitir en combinación con la regla Permitir para bloquear todo en el directorio “/micuenta/” (excepto la página /micuenta/).
User-agent: *
Disallow: /search/
Allow: /search/$
Y nuevamente, dado que Google usa la regla más específica, no permitirá todo lo que esté en el directorio /myaccount/ pero permitirá que solo se rastree la página /myaccount/.
Aquí hay otro caso de uso de combinar las reglas No permitir y Permitir: en caso de que tenga su búsqueda en el directorio /search/ y quiera que se encuentre e indexe pero bloquee las URL de búsqueda reales:
6. Bloquear archivos JavaScript no relacionados con el renderizado
Todos los sitios web utilizan JavaScript y muchos de estos scripts no están relacionados con la representación del contenido, como los scripts de seguimiento o los que se utilizan para cargar AdSense.
User-agent: *
Disallow: /assets/js/pixels.jsEl robot de Google puede rastrear y representar el contenido de un sitio web sin estos scripts. Por lo tanto, bloquearlos es seguro y recomendable, ya que ahorra solicitudes y recursos para recuperarlos y analizarlos.
A continuación se muestra una línea de ejemplo que no permite JavaScript de muestra, que contiene píxeles de seguimiento.
#ai chatbots
User-agent: GPTBot
User-agent: ChatGPT-User
User-agent: Claude-Web
User-agent: ClaudeBot
User-agent: anthropic-ai
User-agent: cohere-ai
User-agent: Bytespider
User-agent: Google-Extended
User-Agent: PerplexityBot
User-agent: Applebot-Extended
User-agent: Diffbot
User-agent: PerplexityBot
Disallow: /#scrapers
User-agent: Scrapy
User-agent: magpie-crawler
User-agent: CCBot
User-Agent: omgili
User-Agent: omgilibot
User-agent: Node/simplecrawler
Disallow: /7. Bloquear chatbots y scrapers de IA
A muchos editores les preocupa que su contenido se utilice injustamente para entrenar modelos de IA sin su consentimiento y desean evitarlo.
Aquí, cada agente de usuario se enumera individualmente y la regla Disallow: / les dice a esos bots que no rastreen ninguna parte del sitio.
Esto, además de evitar el entrenamiento de IA en su contenido, puede ayudar a reducir la carga en su servidor al minimizar el rastreo innecesario.
Para obtener ideas sobre qué bots bloquear, es posible que desees consultar los archivos de registro de tu servidor para ver qué rastreadores están agotando tus servidores y recuerda, robots.txt no impide el acceso no autorizado.
Sitemap: https://www.example.com/sitemap/articles.xml
Sitemap: https://www.example.com/sitemap/news.xml
Sitemap: https://www.example.com/sitemap/video.xml8. Especifique las URL de los mapas del sitio
Incluir la URL de su mapa de sitio en el archivo robots.txt ayuda a los motores de búsqueda a descubrir fácilmente todas las páginas importantes de su sitio web. Esto se hace agregando una línea específica que apunta a la ubicación de su mapa del sitio, y puede especificar varios mapas del sitio, cada uno en su propia línea.
 Asegúrese de que las URL de los mapas del sitio sean accesibles para los motores de búsqueda y tengan la sintaxis adecuada para evitar errores.
Asegúrese de que las URL de los mapas del sitio sean accesibles para los motores de búsqueda y tengan la sintaxis adecuada para evitar errores.Error al recuperar el mapa del sitio en la consola de búsqueda
Error al recuperar el mapa del sitio en la consola de búsqueda
9. Cuándo utilizar el retardo de rastreoLa directiva de retardo de rastreo en robots.txt especifica la cantidad de segundos que un bot debe esperar…
Con información de Search Engine Journal.
Leer la nota Completa > Una guía para Robots.txt: mejores prácticas para SEO





{kind=link}